En lançant OpenAI en 2015, Elon Musk et ses co-investisseurs ne pensaient pas qu’ils allaient déclencher un tel raz-de-marée médiatique quelques années plus tard. Si la vocation initiale d’OpenAI était de s’assurer que l’intelligence artificielle allait bénéficier à l’humanité, force est de constater qu’avec ChatGPT ils ont trouvé la nouvelle Poule aux oeufs d’or, la technologie miracle qui va révolutionner l’informatique et l’humanité. Peut-être est-il temps de prendre du recul par rapport à cette « révolution » et de rappeler certains faits.

Les semaines passent et l’emballement médiatique pour les IA génératives ne semble pas retomber. Pourtant, les avis très mitigés sur la nouvelle version du moteur de recherche de Microsoft se multiplient : Bing Chat is blatantly, aggressively misaligned. Les retours de la communauté sont tellement mauvais que l’éditeur de ChatGPT s’est senti obligé de clarifier ses intentions ainsi que sa feuille de route : How should AI systems behave, and who should decide?
À la décharge d’OpenAI qui adopte une posture de prudence quant à la fiabilité / viabilité de ses modèles génératifs, Microsoft poursuit sur sa lancée et intègre maintenant son IA conversationnelle dans l’application mobile de Bing et dans Skype : Microsoft brings the new AI-powered Bing to mobile and Skype, gives it a voice.

Je ne sais pas ce que ça évoque pour vous, mais j’ai la curieuse impression que Microsoft essaye de relancer tous ses vieux services en y intégrant ChatGPT. C’est un peu comme s’ils essayaient de leur donner un coup de jeune avec une injection de botox ! Tout ceci ressemble furieusement aux pratiques de remballe que l’on retrouve chez certains distributeurs alimentaires qui essayent de refourguer de la marchandise ayant atteint la date limite de consommation. 😬
Au rythme où vont les choses, ils vont bientôt nous ressortir Cortana du placard (leur assistant numérique lancé en 2015) et potentiellement le vieil assistant contextuel de Windows (Why the ghost of Clippy haunts today’s AI chatbots).
Je profite de cette actualité pour à nouveau clarifier certains points, car de nombreux raccourcis trompeurs sont encore utilisés pour décrire les intelligences artificielles ou les modèles génératifs, ainsi que des promesses surréalistes (ex : PwC anticipe un accroissement de la productivité de 45% d’ici à 2030, correspondant à une croissance de la production de valeur de plus de 15.000 MM$ : 2023 Business Predictions As AI And Automation Rise In Popularity).
Rappels sur des notions élémentaires
Avant de nous intéresser aux modèles génératifs, je vous propose dans un premier temps de revenir sur des définitions et explications relatives aux intelligences artificielles, car il subsiste manifestement beaucoup de confusion dans ce que c’est ou ce que ce n’est pas.
Du point de vue du vocabulaire, il est ainsi essentiel de rappeler que les IA ou le machine learning ne sont pas des techniques ou des outils. L’intelligence artificielle est un concept correspondant à des usages. L’apprentissage automatique (machine learning) est un domaine de recherche qui inclut plusieurs familles d’algorithmes. Parmi celles-ci, on retrouve différentes classes de réseaux de neurones artificielles permettant de faire de l’apprentissage profond (deep learning). Cette méthode est notamment utilisée dans le cadre de traitement automatique du langage, ce pour quoi a été créé ChatGPT, un agent conversationnel reposant sur un modèle de langage (GTP) exploitant les transformers (un des types d’architecture de réseaux de neurones artificiels). Vous suivez ? Pour vous y retrouver, je vous propose le schéma suivant :

Maintenant que nous avons une vision d’ensemble, je vous propose de nous arrêter sur des définitions :
- L’intelligence artificielle est un concept technologique visant à utiliser les machines pour simuler l’intelligence humaine, notamment pour des tâches cognitives comme l’analyse ou la déduction. Pour le Parlement européen, l’intelligence artificielle représente tous les outils utilisés pour reproduire des comportements liés aux humains, tels que le raisonnement, la planification et la créativité. Les premiers travaux relatifs à l’intelligence artificielle remontent aux années 1950 avec Alan Turing.
- L’apprentissage automatique est une branche de l’intelligence artificielle utilisant des calculs statistiques pour simuler des capacités d’apprentissage permettant à une machine d’améliorer ses performances dans la résolution de tâches sans avoir été explicitement programmée pour ça. On distingue cinq grandes méthodes d’apprentissage : supervisé, semi-supervisé, non supervisé, renforcé et transféré. L’objectif est d’apprendre aux ordinateurs à apprendre afin qu’ils puissent agir et réagir de façon autonome en fonction des données analysées, tout en améliorant leur modèle de traitement (servant principalement à l’identification de schémas récurrents ou de corrélations au sein de grands volumes de données). Le terme « machine learning » a été utilisé pour la première fois en 1959 par Arthur Samuel, un employé d’IBM.
- L’apprentissage profond est une méthode de machine learning qui permet un apprentissage non supervisé en s’appuyant sur l’analyse de données hétérogènes grâce notamment à des réseaux de neurones artificiels constitués de couches chargées de modéliser ces données de façon simplifiée et non linéaire. Plus le nombre de couches est élevé et plus le réseau est dit « profond ». Le terme « deep learning » a été introduit auprès de la communauté scientifique pour la première fois en 1986 par Rina Dechter, mais dès 1987 notre Yann LeCun national travaillait sur des projets de réseaux de neurones artificiels avec un apprentissage reposant sur la méthode de la rétropropagation.
- Les grands modèles linguistiques (« Large Language Models« , LLM) sont des modèles de traitement automatique du langage reposant sur des méthodes d’apprentissage profond qui sont particulièrement performantes pour la traduction ou la génération de contenus. Le premier modèle de langage a été publié en 2003 par Yoshua Bengio, un français installé depuis de nombreuses années au Québec.
- Les IA génératives utilisent des modèles d’apprentissage profond, et plus précisément les transformeurs qui reposent sur les réseaux de neurones artificiels. Ce sont des modèles auto-attentifs, rendus publics en 2017 par Google, utilisés principalement dans le domaine du traitement automatique du langage (synthèse, traduction, dialogue…). À l’instar des réseaux de neurones récurrents (RNN pour « Recurrent Neural Network« ), les transformeurs sont conçus pour gérer des données séquentielles, telles que le langage naturel. Contrairement aux RNN, les transformeurs n’exigent pas que les données soient traitées dans l’ordre. Cela permet une parallélisation beaucoup plus importante que les RNN et donc des temps d’entraînement réduits. Dans la mesure où les modèles transformeur facilitent la parallélisation pendant la phase d’entraînement, celle-ci peut s’effectuer sur des ensembles de données plus volumineux. Ce gain de temps a conduit au développement de systèmes pré-entraînés tels que BERT et GPT, des modèles créés à partir d’énormes ensembles de données de texte général, tels que le Wikipedia Corpus.
Comme vous pouvez le constater, l’intelligence artificielle et plus particulièrement l’apprentissage automatique sont des domaines extrêmement riches et variés, mais surtout beaucoup plus anciens qu’on ne le pense. En matière de recherche et d’applications, les méthodes utilisées varient en fonction des ressources informatiques disponibles. Ainsi, avec la généralisation du cloud computing et de formidables puissances de calcul disponibles à bas prix, les efforts se concentrent ces dernières années sur les modèles de langage étendus qui sont ceux qui fournissent les meilleurs résultats par le biais de déclinaisons pour assurer des traitements particuliers (traduction, résumé, génération d’images ou de texte…).
Le fonctionnement des IA génératives est assez cocasse : elles génèrent un mot à la fois en fonction du contexte de la phrase sur la base d’un calcul probabiliste. Dans les faits, il y a bien évidemment des subtilités, mais le procédé revient à « deviner » les mots les uns à la suite des autres, les nouveaux mots étant choisi selon leur correspondance statistique avec les mots précédents. Traduction : à chaque nouveau mot, le modèle cherche quel est celui qui a été le plus utilisé dans sa base de connaissances avec une phrase plus ou moins similaire : What Is ChatGPT Doing and Why Does It Work?

Les contenus générés sont ainsi trompeurs, car malgré une syntaxe parfaite (qui nous font croire à un niveau d’instruction élevé, donc une forme de savoir), les modèles génératifs ne savent pas vraiment ce qu’ils racontent dans la mesure où ils ne s’appuient pas sur des bases de connaissances structurées à l’aide d’un thesaurus (au contraire du knowledge graph de Google). Ceci étant dit, et je le répète, les contenus générés font parfaitement illusion, car les modèles savent très bien analyser le contexte de la phrase, ou du moins des phrases, car des modèles comme ChatGPT prennent en compte une « fenêtre contextuelle » de plus de 3.000 mots. Pour améliorer la compréhension du contexte, il suffit d’augmenter la taille de la fenêtre contextuelle (plus de puissance de calcul) ainsi que la richesse du vocabulaire employé (plus de données d’apprentissage).
Nous assistons logiquement à une véritable course à l’armement dont la prochaine étape sera la sortie de GPT-4 et ses 100 trillions de paramètres, où nous atteindrons officiellement le pic des attentes exagérées (OpenAI CEO Sam Altman on GPT-4: ‘people are begging to be disappointed and they will be’).

Maintenant que nous avons (re)défini le cadre général de l’intelligence artificielle, nous pouvons aborder le sujet des IA génératives.
« Conversational AI » is (not) the new « Digital Assistant »
Lancé en fin d’année 2020, ChatGPT est la nouvelle sensation du monde des technologies de l’information (ChatGPT: Optimizing Language Models for Dialogue). Présenté à tort comme une technologie ou comme un algorithme, la description la plus pertinente serait de le définir comme une interface : un dispositif informatique qui permet aux utilisateurs d’exploiter un modèle de langage (GPT).

Autant le dire tout de suite : non, ChatGPT n’est pas une technologie révolutionnaire, c’est la version publique d’un projet de recherche qui a bénéficié de plusieurs décennies d’amélioration. Je ne remet absolument pas en cause la qualité des contenus que ChatGPT est capable de générer, mais je m’offusque contre le fait de nous présenter ça comme une innovation inédite dans l’histoire de l’informatique (La révolution des IA génératives n’aura pas lieu, ou pas comme on essaye de nous la vendre).

De façon assez surprenante, on nous présente cette IA conversationnelle comme une innovation de rupture, pourtant les chatbots existent depuis de nombreuses années. Pour être plus précis : les agents conversationnels existent depuis le début des années 1970, se sont des logiciels capables de dialoguer avec des utilisateurs à travers une interface textuelle ou vocale.
Des « agents conversationnels à interface vocale », ça ne vous rappelle rien ? Dès 2016, les assistants vocaux ont ainsi commencé à être disponibles auprès du grand public par le biais des smartphones et enceintes connectées (cf. Chatbots et assistants personnels façonnent le web de demain et Usages et enjeux des interfaces vocales), un marché rapidement dominé par les géants numériques qui ont su éliminer la concurrence grâce à leur mainmise sur les terminaux (Comment les interfaces vocales vont accélérer la transformation digitale).
Des nombreux assistants vocaux lancés à cette époque (ceux de Apple, Google, Amazon, Samsung, Microsoft, Baidu, Tencent, Yandex, Orange…), seuls ceux des BigTechs sont encore utilisés, mais de façon restreinte. Qu’à cela ne tienne, ceci n’explique pas le phénomène d’amnésie que l’on peut constater auprès de tous ceux qui s’émerveillent devant ChatGPT. Nous sommes ici clairement en train de réinventer la roue.
Pour appuyer mes propos, je précise que les assistants numériques ne datent pas de 2016, puisque Siri existait sous forme d’application indépendante en 2010, rachetée rapidement par Apple et intégrée à iOS en 2011 pour le lancement de l’iPhone 4S. Encore plus surprenant : le concept d’assistant numérique utilisé dans le cadre de recherche d’informations ou d’exécution de tâches simples a été décrit pour la première fois en 1987 par John Sculley, l’ancien CEO de Apple, dans un livre où il mentionne les “Knowledge Navigators« .
// Interlude patrotique
Saviez-vous que l’un des fondateurs de la société qui a développé Siri est un français ? Je pense qu’entre Yann Lecun, Yoshua Bengio et Luc Julia, la France peut-être très fière des cerveaux qu’elle a vu naitre. 👏🏻 🇫🇷 🐓
// Fin de l’interlude patriotique
Tout ça pour dire qu’assistants vocaux, chatbots et IA conversationnelles désignent grosso modo la même chose (un outil informatique auquel on pose des questions pour obtenir des réponses), mais sous des formes différentes (accessibles à travers des interfaces distinctes). Et encore, je ne mentionne pas les agents conversationnels que l’on croise sur les sites web depuis deux décennies dont certaines sociétés comme iAdvize en ont fait leur spécialité depuis 2010. Je me demande comment ils doivent réagir à cet emballement médiatique autour de ChatGPT… probablement de la même façon qu’il y a 7 ans avec la mode des chatbots…
Puisque l’on parle du loup, il est temps de nous intéresser aux assertions que l’on peut lire ou entendre dans les médias.
Bientôt la fin de la ChatGPT mania ?
Comme précisé en début d’article, je vous propose de rétablir quelques vérités, ou du moins de nuancer l’enthousiasme de certain(e)s.
Les IA conversationnelles sont-elles des technologies révolutionnaires ?
Comme précisé plus haut, non, ce ne sont pas des technologies, mais des applications de différentes méthodes d’apprentissage automatique. Les IA conversationnelles comme ChatGPT ou le nouveau Bing sont très impressionnantes, mais elles n’ont rien de révolutionnaire, car elles sont la résultante de décennies de recherches et d’améliorations.

Les IA génératives sont-elles magiques (capables de faire des choses impossibles pour les humains) ?
Bien évidemment que non, vous vous croyez dans Harry Potter ? Il n’y a rien de magique dans le fonctionnement des modèles génératifs, c’est juste beaucoup de puissance de calcul pour ingurgiter une masse colossale de contenus (triés et filtrés par des Kenyans payés 1$ de l’heure) et régurgiter des réponses à travers une interface textuelle. Il en va de même pour les modèles générateurs d’images comme DALL-E : sans les données d’entraînement, les images et illustrations créées par des humains, ces modèles n’existeraient pas.

ChatGPT et-il une innovation de rupture ?
Non, ChatGPT n’a rien de révolutionnaire, c’est la déclinaison en agent conversationnel de GPT, le modèle linguistique étendu sur lequel travaillent les équipes d’OpenAI depuis 2015 et dont ils sont à la quatrième version (si l’on tient compte de GPT 3.5 lancé en fin d’année dernière). Nous sommes clairement ici dans le cadre d’une amélioration continue, pas dans de l’innovation de rupture. D’autant plus qu’il existe d’autres modèles génératifs à interface textuelle avec des offres déjà packagées comme celui proposé par Jasper.

Les IA génératives sont-elles une source de création de valeur ?
On nous explique que les IA génératives vont faire notre travail à notre place, mais c’est loin d’être le cas, car elles n’assurent qu’une partie du travail (lisez bien entre les lignes de cet article : From CEOs to Coders, Employees Experiment With New AI Programs).
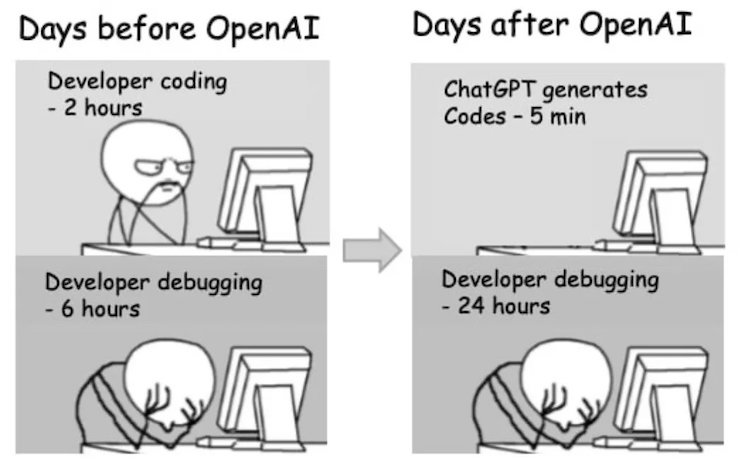
De plus, si les IA génératives peuvent effectivement nous faire gagner du temps, elles ne peuvent être considérées comme des outils de production « standards », car il y a des enjeux juridiques. Comprenez par là que les contenus générés par les IA ne peuvent pas être exploités commercialement : The US Copyright Office says you can’t copyright Midjourney AI-generated images.
Le nouveau Bing va-t-il remplacer Google ?
Au cas où vous l’auriez oublié, Bing tente de concurrencer Google depuis 2009. La nouvelle version du moteur de recherche de Microsoft repose sur une promesse très forte, mais se heurte à de nombreuses difficultés techniques, juridiques et éthiques pour un déploiement à grande échelle (Generative AI Won’t Revolutionize Search, Yet).
Une question plus pertinente aurait été de se demander si avec ChatGPT, Microsoft allait relancer Cortana pour concurrencer l’Assistant Google, mais un assistant vocal se heurtera aux mêmes enjeux juridiques et éthiques. De plus, la concurrence ne se réduit pas aux BigTech, car il existe déjà d’autres services grand public comme You ou Andi.

ChatGPT va-t-il révolutionner Windows et Office
Encore une fois, si les modèles génératifs offrent des perspectives d’amélioration très alléchantes, il y a longtemps que l’intelligence artificielle est utilisée dans les outils de la suite Office (ex : correction grammaticale dans Word, complétion de suite de données dans Excel…) ou même dans Windows (ex : intégration de modèles de machine learning dans les applications Windows grâce à Windows ML ou Direct ML : Get Started with Windows Machine Learning). Donc, comme pour les points précédents : pas de révolution, mais une amélioration de l’existant. Idem pour les applications en ligne proposées par Google : 6 Vital Ways Google Apps Use AI to Help You Every Day.

Le nouveau Edge va-t-il remplacer Chrome ?
Le navigateur de Microsoft représente moins de 5% de parts de marché. C’est un problème, car les habitudes des internautes sont très dures à changer (et ce n’est pas en incrustant des bandeaux publicitaires qu’ils vont y parvenir : Microsoft is now injecting full-size ads on Chrome website to make you stay on Edge). Pour vous en convaincre, il suffit de regarder le faible taux d’adoption de Firefox, voire de Safari, qui offrent de meilleures performances sur Windows et Mac. De plus, intégrer un agent conversationnel à un navigateur n’est pas une fonctionnalité unanimement réclamée par les utilisateurs (d’autres navigateurs alternatifs essayent de leur côté : Opera’s building ChatGPT into its sidebar). De façon plus générale, les navigateurs proposant des fonctionnalités additionnelles ne passionnent pas les foules (cf. Arc ou Vivaldi), la tendance est plus d’optimiser les performances des navigateurs, et notamment de minimiser la consommation de mémoire ou d’énergie (à ce sujet : Google Chrome rolls out long awaited battery saving features).
Les modèles génératifs vont-ils remplacer les ordinateurs ?
Croyez-le ou non, mais certains prédisent un futur proche où tout ce dont nous aurons besoin, c’est de dicter des ordres à voix haute pour effectuer telle recherche ou telle tâche. De ce fait, plus besoin des ordinateurs traditionnels avec clavier et souris. Effectivement, dans la mesure où les tablettes et formats hybrides existent depuis plus de 10 ans, nous sommes en droit de questionner l’utilité des PC et périphériques informatiques traditionnels (Avons-nous encore besoin des ordinateurs et imprimantes ?). Ceci étant dit, le principal facteur de transformation des usages et attentes n’est pas l’intelligence artificielle ou les modèles génératifs, mais le fait que l’essentiel de notre travail est maintenant effectué dans des applications en ligne.
De façon contre-intuitive, c’est plutôt l’inverse qui va se produire : le marché va se scinder entre des tablettes toujours plus légères pour accéder à des applications en ligne (dopées à l’IA) et des ordinateurs toujours plus puissants pour faire tourner des modèles génératifs en local (calculs prédictifs, suggestions et génération de contenus…). En ce sens, nous allons logiquement assister à l’élaboration de modèles linguistiques compacts qui seront intégrés nativement dans les ordinateurs (ex : le modèle publié récemment par Amazon qui offre des performances 16% supérieure à GPT 3.5 pour une taille équivalent à 0,3 % : Multimodal Chain-of-Thought Reasoning in Language Models, idem pour Facebook : Meta unveils a new large language model that can run on a single GPU). Et peut-être qu’un jour prochain ils arriveront à les faire rentrer dans un smartphone (Qualcomm demos fastest local AI image generation with Stable Diffusion on mobile).
Une recherche synthétique coûte-t-elle moins cher qu’une recherche traditionnelle ?
Contrairement à ce que j’avais écrit dans mon dernier article, les agents conversationnels de recherche ne consomment pas moins d’énergie que les recherches traditionnelles. L’explication est plutôt simple : une fois créé et optimisé, la consultation d’un index ne consomme que très peu d’énergie (ça fait 20 ans que Google améliore l’efficience de l’infrastructure technique de son moteur de recherche), contrairement à un modèle dont la phase d’entrainement est très énergivore et dont chaque inférence nécessite des traitements beaucoup plus importants, car les mots sont générés les uns à la suite des autres à l’aide de calculs probabilistes : ChatGPT-style search represents a 10x cost increase for Google, Microsoft.

Les IA vont-elles révolutionner l’informatique ?
Non, car elles le font déjà depuis des décennies. De plus, jusqu’à preuve du contraire, les intelligences artificielles restent des programmes informatiques, c’est donc un abus de langage. Mais de façon plus pragmatique, si l’intégration de modèles génératifs dans les outils et logiciels en ligne est très prometteuse, c’est déjà une réalité depuis de nombreuses années avec Watson chez IBM, Einstein chez SalesForce ou Sensei chez Adobe. Dans tous ces exemples, l’IA n’est qu’une fonctionnalité ajoutée à d’autres, il n’y a pas de remplacement, mais un enrichissement.
Vous noterez au passage la disponibilité de Notion.ai, l’intégration effective d’un modèle génératif dans cet outil de collaboration (annoncée l’année dernière : Notion is using AI to automatically write your blog posts, job descriptions, and poetry).

Les modèles génératifs vont-ils détruire de nombreux emplois ?
Cette question a déjà été abordée à de nombreuses reprises à l’époque où le grand public découvrait le machine learning, mais visiblement on ne se lasse pas de la poser (idem pour l’automatisation avec des robots qui sont utilisés dans l’industrie depuis le début des années 1960). Je formule donc les mêmes réponses : que ce soit pour des contenus textuels ou des images, la production des modèles génératifs (ou des IA en général) n’est pas directement exploitable, car elle nécessite un minimum de travail pour relire, confirmer, reformuler, retoucher… (cf. Publisher editorial teams experiment with ChatGPT, but few use AI tech in their work et ChatGPT Is About to Dump More Work on Everyone).
De façon plus générale, ce ne sont pas les modèles génératifs ou les IA qui détruisent des emplois, mais les charges salariales et patronales. Face à des montants toujours plus élevés, les employeurs cherchent à réduire leur masse salariale et suppriment petit à petit des postes en reportant la charge de travail sur les clients (ex : caisses automatiques, distributeurs à billets, bornes interactives…). Est-ce un fléau ? Non, plutôt un signe des temps. Souvenez-vous qu’à une époque, il y avait des employés dans les ascenseurs des grands hôtels pour appuyer sur les boutons à la place des clients.

Plutôt que de nous soucier de l’impact des IA sur nos emplois, nous devrions plutôt nous soucier de leur impact sur nos habitudes et des conséquences : Le nouveau Bing est-il un danger pour l’humanité ?
Les modèles génératifs vont-ils aider à construire le métavers ?
Créer un environnement virtuel à la fois riche et réaliste demande énormément de temps et de ressources. C’est précisément dans ce cas d’usage que les modèles génératifs vont se révéler particulièrement intéressants pour reproduire l’existant (L’IA pour enrichir les métavers et proposer des expériences de marque valorisantes). Donc oui, c’est clairement dans cette direction qu’il faut regarder, notamment pour les jeux vidéo (How generative AI is changing game development), et pas dans celle de la recherche où nous avons déjà des moteurs qui fonctionnent très bien.

Les IA génératives sont-elles l’avenir du Web3 (et inversement) ?
Non. Rien à voir.
—
Ceci conclut donc mes explications, ou du moins mes tentatives d’explications sur des concepts et pratiques extrêmement complexes et pointus. J’espère vous avoir éclairé sur ce vaste sujet, et surtout vous avoir fournit les clés de compréhension pour ne pas vous laisser abuser par des vendeurs de solutions miracles et autres prophètes de la Grande Révolution Techniques. Car ce temps-là, on ne parle pas des sujets qui vont réellement bouleverser le web et les services en ligne : le blocage des identifiants publicitaires (cookies ou UserID sur smartphone). Ça sera d’ailleurs le sujet de mon prochain article.