Voilà 20 ans que l’on nous parle de cloud computing, une approche révolutionnaire de l’informatique. Après deux décennies de croissance ininterrompue et de sophistication des offres et solutions technologiques, les entreprises se retrouvent généralement avec un système d’information encore plus hétérogène qu’avant ! Mais ce n’est pas un problème, car les applications et données hébergées dans le cloud sont beaucoup plus faciles à manier, le souci vient plus des applications et données qui n’ont pas encore été basculées. Un chantier urgent, car la période d’instabilité et d’incertitudes que nous traversons exige une grande souplesse et beaucoup de réactivité pour s’adapter aux nouvelles habitudes et contraintes des consommateurs, ainsi que pour exploiter au mieux les opportunités offertes par les outils numériques et les données qu’ils génèrent.

Alors que l’été se profile, la crise sanitaire semble résolument derrière nous : plus de couvre-feu, plus besoin de porter le masque, assouplissement des jauges dans les commerces et restaurants, réouverture prochaine des boites de nuit, retour progressif au bureau (3 jours par semaine)… L’heure est très clairement à la reprise, car les indicateurs sont enfin au vert (cf. le World Uncertainty Index qui est aujourd’hui plus bas qu’en 2018).
Problème : les habitudes des consommateurs ont irrémédiablement changé et certaines contraintes subsistent. Il semble improbable d’appliquer les recettes du siècle dernier dans un quotidien sans contact où les supports et outils numériques sont omniprésents, et pourtant… nombreux sont ceux qui essayent par la force de l’habitude. Impossible non plus d’utiliser les méthodes et outils du XXe siècle dans une économie à la demande, et pourtant…
À l’époque industrielle (19e et 20e siècles), le coeur d’une entreprise battait au rythme de sa capacité de production. On parlait alors de takt time pour désigner la durée idéale de production d’un bien (un terme d’origine allemande : « Taktzeit »). Nous sommes maintenant au 21e siècle, dans une économie dominée par les services (ces derniers représentant plus de 80% du PIB), il convient alors de redéfinir la durée idéale de production. J’imagine ce que vous devez vous dire : le plus court sera le mieux ! Mais ce n’est pas si simple, car tout va dépendre des processus et du système d’information sur lequel ils reposent.
De l’importance des données dans une économie ultra-compétitive reposant sur les services
Avec la quatrième révolution industrielle, celle du numérique, les moteurs de l’économie (ceux qui cumulent croissance et rentabilité) ne sont plus les grands acteurs industriels, mais les géants du numérique. On pense bien évidemment aux GAFAM, à leurs profits faramineux et à la logique tentative des pays européens de faire émerger leurs licornes. Mais les avantages que l’on peut tirer du numérique s’appliquent également aux autres organisations. Très clairement, ce qui va conditionner le succès d’une entreprise n’est plus la qualité de production, mais la qualité de l’expérience. Plus les collaborateurs de première ligne, ceux qui sont au contact des clients, sont équipés d’outils performants et d’informations pertinentes, meilleure sera la qualité des services rendus et des prestations délivrées, donc de l’expérience globale. Nous pouvons ainsi facilement faire le lien entre un SI limité et la qualité de l’expérience client.
Nous pouvons également faire un lien direct avec la performance : plus le SI d’une entreprise est lourd, et plus vite elle va atteindre sa capacité maximale de production (de biens ou de services). Et je mets au défi quiconque de me prouver le contraire ! Nous pouvons enfin compléter ceci avec une dernière assertion : plus le SI d’une entreprise est rigide, moins elle aura de marge de manoeuvre pour optimiser l’expérience client ou augmenter cette capacité maximale de production.

Tout ça pour dire que le centre de gravité des entreprises s’est déplacé de ses lignes de production vers son système d’information. Une observation en phase avec les fameuses réflexions de Marc Andreessen (« Software is eating the world« ) et de Satya Nadella (« Every Company is Now a Software Company« ).

À mesure que les usines d’hier sont petit à petit remplacées par des data centers, les applications et données deviennent des actifs immatériels stratégiques pour les entreprises. À ce sujet, j’ai eu l’occasion de participer cette semaine à l’événement Discover organisé par HPE à l’occasion de récentes annonces (HPE expands GreenLake with new cloud services, silicon on demand and more) et de la poursuite de leur repositionnement sur du « Everything-as-a-Service » (HPE CEO: In the Future, It’s Just GreenLake), ce qui m’a permis d’y voir un peu plus clair dans les dernières tendances et surtout les enjeux actuels des entreprises.
Une rediffusion de la table ronde est disponible ici : HPE Discover 2021 – Perspectives for the French Market.
De l’intérêt de mettre ses données et applications à l’abri dans le cloud
Nous avons malheureusement assisté ces dernières années à une recrudescence des piratages informatiques. Une activité devenue très rentable qui pousse les pirates à s’organiser et à concentrer leurs efforts sur des cibles critiques : hôpitaux (Pourquoi des cyberattaques ciblent-elles les hôpitaux ?), gouvernements (Cyber attack ‘most significant on Irish state’), infrastructures (Here’s the hacking group responsible for the Colonial Pipeline shutdown)… Le coût des cyberattaques devrait rapidement dépasser les 10 billions de $ (Cybercrime To Cost The World $10.5 Trillion Annually By 2025) avec en moyenne 3,86 M$ pour les entreprises (The cost of a cyber attack in 2021).
La sécurité est donc une problématique critique, et une excellente raison de passer au cloud, mais pas que ! Ainsi, comme nous l’avons vu précédemment, un système d’information rigide et limité est assurément un problème pour tout ce que vont chercher à faire les entreprises. Voilà pourquoi le cloud est un marché si dynamique dont les revenus culminent à 42 MM$ : Global cloud services market in Q1 2021. Ceci étant dit, les choses se compliquent dès que l’on essaye de détailler ce que l’on entend par « cloud ». Il y a 10 ans, j’avais fait une modeste tentative de cadrage du sujet : Définition et usages du cloud computing. Aujourd’hui, les choses se sont considérablement complexifiées, car le cloud est disponible sous différentes formes, en fonction de ce que l’entreprise veut ou sait faire. Pour vous permettre de saisir toutes les subtilités de l’offre cloud, je vous propose cette excellente analogie sur le Pizza-as-a-Service : SaaS, PaaS and IaaS explained in one graphic.
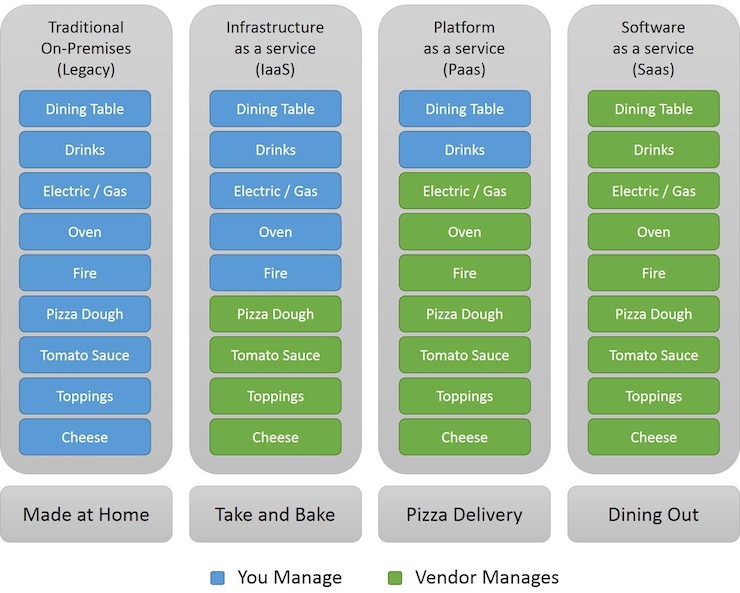
Comme vous pouvez le voir dans ce schéma, le cloud peut être adopté complètement (colonne de droite), partiellement (colonnes centrales) ou pas du tout (colonne de gauche). Avec cette image en tête, vous pouvez maintenant transposer ça dans le monde de l’informatique d’entreprise et comprendre la différence entre les différents modèles (IAAS, PAAS, SAAS, DAAS, BAAS : quel modèle cloud choisir pour vos solutions de performance industrielle ?).
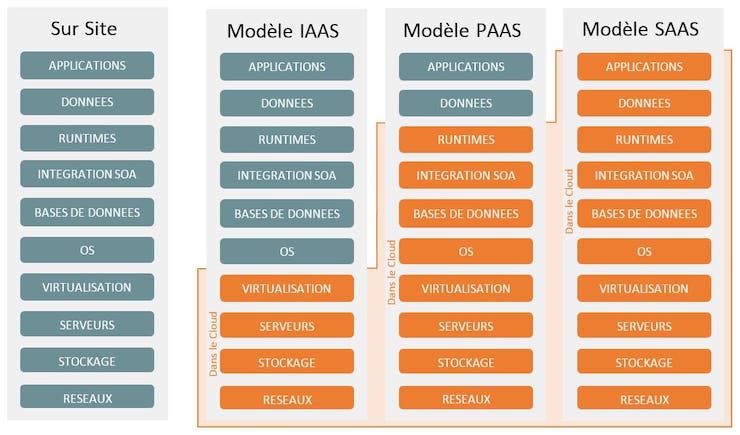
Ce tableau comparatif illustre bien la diversité de l’offre (quoi qu’il existe des colonnes intermédiaires) et surtout la façon dont les architectures cloud se sont complexifiées au fil des années. 20 ans après la création des premières offres, les entreprises et organisations ont basculé une part toujours plus importante de leur système d’information dans le cloud pour pallier aux limitations de leurs infrastructures internes, mais sont maintenant confrontées à d’autres types de problèmes.
Les principaux enjeux que l’on peut lister en 2021 sont les suivants :
- Disponibilité. Selon Eurostat, 1/3 des entreprises en Europe ont adopté le cloud, donc 2/3 ne l’ont pas encore fait (Europe Cloud Computing Market Report). On estime que la moitié des applications ont migré, mais quid du reste dans la mesure où 78% des salariés français souhaitent travailler différemment (Hybride, flexible, à impact : voilà comment vous voyez le travail demain) ?
- Rentabilité. Le modèle de paiement à l’utilisation est très intéressant, mais l’addition peut vite grimper si l’on ne se méfie pas un minimum. Optimiser les performances et les coûts des applications déjà hébergées sera une tâche de première importance pour les entreprises dont une grosse partie des dépenses IT est happée par le cloud (des dépenses en croissance moyenne de 35% en un an : Cloud computing, les dépenses atteignent des sommets en 2020).
- Souveraineté. D’après Calanys, les 3 grands acteurs US représentent 58% du marché (Global cloud services market surges by US$10 billion in Q4 2020). Il y a donc une nécessité de lutter contre cet oligopole, et de reprendre le contrôle des applications (d’où le label « Cloud de confiance » instauré par le Gouvernement) ainsi que de rapatrier les données (cf. le « European Cybersecurity Certification Scheme for Cloud Services« ).
- Portabilité. On estime que moins de la moitié des applications hébergées dans le cloud sont isolées au sein de containers (Taking Cloud-Native Security to the Next Level), ceci limite fortement la capacité des entreprises à changer de fournisseur, car les frais de migration sont prohibitifs.
- Intégration. Maitriser une architecture multicloud est devenu une priorité pour 70% des DSI interrogés au même titre que la montée en charge. Si le multicloud séduit il n’en demeure pas moins que la trajectoire qui y mène n’est pas un long fleuve tranquille. Entre 30 à 37% des entreprises rencontrent d’importantes difficultés à réaliser l’intégration entre différents clouds. Ces besoins d’intégration n’ont souvent pas été pris en cause et expliquent en partie le fait qu’au dernier trimestre 2020, 58% des entreprises s’attendaient à voir leur budget cloud dépassé (Public Cloud IT Infrastructure Revenue Growth Remained Strong).
Cette liste d’enjeux n’est pas exhaustive, car à chaque entreprise correspondent des difficultés ou axes d’optimisation en rapport avec les solutions cloud. En règle générale, je pense ne rien vous apprendre en écrivant que la migration vers le cloud n’est pas une solution miracle, c’est même une phrase qui ne veut plus rien dire tant le sujet est vaste et couvre des situations et technologies variées. À ce sujet, vous seriez surpris d’apprendre qu’il y a « cloud » et « cloud ».
Du cloud au edge en passant par le fog
Avec la multiplication des objets et capteurs connectés (ente 30 et 40 milliards selon les estimations), le nombre et la variété de sources a augmenté de façon exponentielle. Il en résulte des besoins qui ne sont plus forcément couverts par les offres historiques du cloud.

Avec la miniaturisation des composants, l’idée a été avancée de transférer une partie de la charge de travail (l’analyse des données) directement sur les terminaux qui captent la donnée. Par opposition aux ressources informatiques distantes et centralisées du cloud computing, le edge computing se définit comme l’utilisation de ressources informatiques à la périphérie, là où se trouvent les données : IoT at the Network Edge.
L’idée est bonne, très bonne même (notamment dans les applications industrielles ou les véhicules autonomes), mais elle est également intéressante pour les entreprises qui ont besoin d’une très forte disponibilité et qui souhaitent éviter de développer une dépendance aux géants américains. La solution consiste donc à exploiter des ressources informatiques de proximité.
Selon cette optique, nous nous retrouvons avec une architecture à trois niveaux : des data centers gigantesques pour les gros traitements (big data) ou l’archivage ; des data centers plus petits appelés « nodes » (« noeuds » dans la langue de Molière) , mais plus nombreux et à proximité immédiate pour les traitements de données critiques ; et enfin, des terminaux capables d’effectuer la captation et le traitement des données en local : Fog and edge computing adds new dimension to the cloud.

Autant vous le dire tout de suite : je ne suis pas du tout à l’aise avec l’appellation « fog computing » qui véhicule une connotation vaporeuse aux équipements et traitements qui peuvent être réalisés en périphérie. Voilà pourquoi je préfère parler de « cloud computing de proximité » ou tout simplement d’associer ça au edge computing. Mais cela peut prêter à confusion, car les applications que vous utilisez sur votre smartphone relèvent du edge computing, hé oui !
Je tiens à préciser que le edge computing ne s’applique pas que aux acteurs de l’industrie ou des transports qui ont besoin de traitements complexes en temps réel, mais également à d’autres secteurs où une partie des traitements peut être effectuée sur-place. Par exemple dans la distribution où les points de vente sont de plus en plus connectés : Retail’s evolution depends on edge computing. Dans tous les cas de figure, l’idée est bien de répartir la charge de travail : analyse de grands volumes de données et définition d’un modèle de traitement dans le cloud, exploitation et affinage du modèle dans le edge.
Sur le papier, ça fonctionne parfaitement, comme toujours, mais dans la réalité, les entreprises se retrouvent avec une configuration à plusieurs niveaux qui repose sur une multitude d’applications en ligne éditées par des sociétés différentes et des services d’hébergement traditionnels mais auprès de fournisseurs différents (multi-cloud). Le tout devant cohabiter avec des applications et systèmes historiques (cloud hybride). Tout ceci forme un magnifique entrelacs que l’on a le plus grand mal à cartographier et à piloter. D’où le recours à des outils de supervision pour pouvoir surveiller le bon fonctionnement et optimiser les performances / coûts (Les « cloud management platforms », compléments utiles de votre gestion multicloud).
Malgré tout, la sécurité reste le principal argument en faveur de ces solutions, mais il faut également prendre en compte la souplesse et la modularité des architectures distantes. Exactement ce dont les entreprises ont besoin pour relever les défis mentionnés en début d’article (notamment le passage du mass marketing au data marketing).
De la nécessité de développer de nouvelles capacités de traitement des données
Comme nous l’avons vu précédemment, la maitrise de la donnée est un élément-clé pour les entreprises, un facteur critique qui conditionne leurs performances. Si les solutions et offres de cloud ne manquent pas pour la partie matérielle, la partie opérationnelle est plus délicate (identification, collecte, stockage, préparation et exploitation). En effet, toutes les données ne se valent pas : 90% des données ne sont pas structurées (90 Percent of the Big Data We Generate Is an Unstructured Mess) et 60% sont dans des entrepôts de données ou équivalents (data warehouses et data lakes). Ce qui veut dire que 40% des données sont éparpillées on ne sait pas trop où (ex : dans les fichiers des PC des collaborateurs, dans leurs emails… cf. Cloud integration: shining a light on dark data).
Par opposition aux lacs de données, les professionnels du milieu parlent de marais de données : Getting Rescued From the Data Swamp. Oui je sais, cette utilisation abusive des analogies peut faire sourire, mais elle repose sur une réalité opérationnelle (Data lakes and data swamps), même si des fois, ils abusent carrément (What is a Lakehouse?).
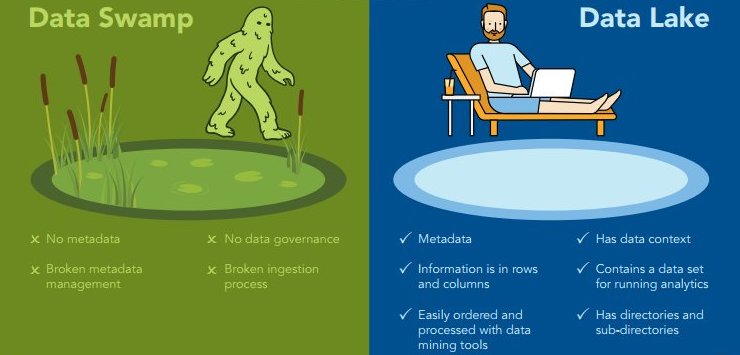
Parler de la façon dont sont stockées les données permet de parler de la donnée elle-même, de ce que l’on doit / peut faire avec et de sa valeur intrinsèque. Dans l’absolu, il n’y a pas de bonnes ou mauvaises données, car la donnée est une matière première qui peut se travailler, comme le sable que l’on trouve en abondance dans le désert, donc qui n’a pas de valeur, mais qui peut être transformé en verre (cf. Data is the New Sand de Tim O’Reilly).
Nous pouvons ainsi distinguer différents types ou « états » de la donnée au sein d’une entreprise ou organisation :
- les small data, celles qui sont compréhensibles par un humain et peuvent être stockées sur un seul ordinateur (ex : fichiers bureautiques) ou sur un serveur (ex : les jeux de données que l’on exporte d’un progiciel) ;
- les big data, celles qui sont beaucoup trop volumineuses pour être stockées sur une seule machine et sont trop hétérogènes pour être lisibles par un humain (ex : les innombrables citations et commentaires relatifs à une marque sur les médias sociaux) ;
- les dark data, celles qui ne sont pas accessibles (ex : les messages échangés sur les applications de messagerie qui sont cryptés, donc qu’une marque ne peut pas analyser) ou que l’on a oubliées (ex : les vieux fichiers sur un serveur partagé ou les données d’une application en ligne que l’on n’utilise plus) car elles ne semblent avoir à priori aucune valeur ;
- les smart data, celles qui sont nettoyées, enrichies et disponibles pour alimenter les outils d’aide à la décision ou d’automatisaton.
Comme vous l’imaginez, le but de toute entreprise est de développer de nouvelles capacités de collecte et traitement des données pour transformer de la matière première brute (big data) en ressource exploitable (smart data), et d’enrichir des jeux de données limités (small data) avec des données jusqu’alors coincées dans les limbes des systèmes d’information (dark data).

Sur le papier, mon schéma fonctionne très bien, mais dans le quotidien d’une entreprise, cela représente beaucoup de travail (identification, collecte, nettoyage…), et nécessite des compétences pointues (data literacy) ainsi que le hardware / software adéquat (cloud et edge computing).
Qu’à cela ne tienne, dans la mesure où c’est une condition de survie pour bon nombre d’entreprises qui doivent faire face à une concurrence acharnée, elles doivent impérativement « muscler leur jeu ». Ceci passe nécessairement par un grand chantier cloud / data, une authentique révolution informatique qui nécessite à la fois une volonté forte de la Direction Générale (mobilisation de moyens importants, définition d’objectifs et de nouvelles façon de travailler / prendre des décisions…) et des ressources dédiées (informatiques et humaines). Ce dernier point me semble particulièrement critique (La donnée est un enjeu majeur de l’accélération digitale) et je n’insisterai jamais assez sur la nécessité de diffuser une culture de la donnée et de définir une stratégie data viable (vision / ambitions / objectifs), surtout en cette période si critique et complexe.
Pour conclure, je vous propose de méditer sur cette citation de Bill Hewlett et David Packard, les fondateurs de HP, qui résonne parfaitement avec le contexte actuel : « The biggest competitive advantage is to do the right thing at the worst time« .