Voilà maintenant près de 5 ans que l’on parle du web 2.0 (ce terme a pour la première fois été utilisé en 2004 lors du Web 2.0 Summit) et depuis le grand jeu a été de savoir quand arrivera la prochaine itération. Pour faire simple disons que le web 2 .0 était le terme utilisé dans les années 2006/2007 pour décrire un changement majeur dans les usages de l’internet (voir ma dernière définition en date). Ce dernier repose sur deux notions fondamentales: l’intelligence collective, le web comme une plateforme (pour les utilisateurs et les services). Maintenant ce terme est passé de mode et l’on emploie plus volontiers celui de médias sociaux qui sonne moins « informatique » à l’oreille. J’ai également eu l’occasion de faire un panorama des différents services associés aux médias sociaux ainsi que de donner une définition.
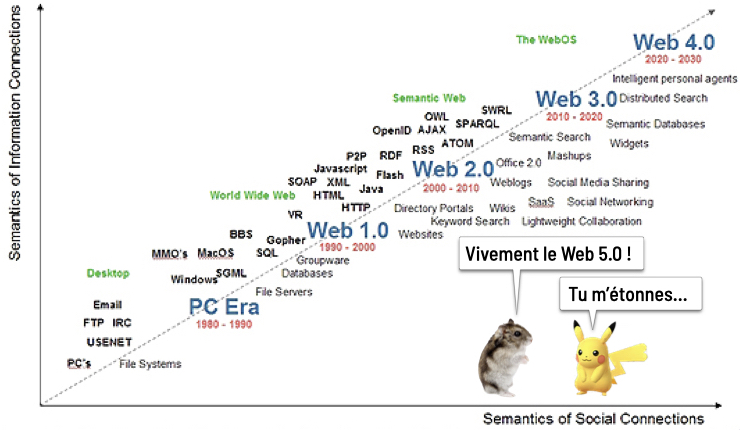
L’étape suivante a logiquement été d’anticiper le web 3.0 (dont j’ai également tenté de donner une définition en 2006) qui repose sur le concept de web sémantique avec le découpage suivant qui est communément admis :
- Web 1.0 = plateforme pour les documents
- Web 2.0 = plateforme pour les individus
- Web 3.0 = plateforme pour les données
A la vue du chantier titanesque que représente la re-sémantisation du web (nous parlons d’un horizon à 5 ou 10 ans) et des avancées dans d’autres domaines, Tim O’Reilly et John Battelle ont proposé une appellation intermédiaire lors du dernier Web 2.0 Summit : Web Squared: Web 2.0’s Successor?
L’idée étant de regrouper différentes avancées majeures derrière un terme unique pour pouvoir capitaliser dessus et évangéliser le marché. D’où la nouvelle notion de Web² (Web au carré, « Web Squared » en anglais) qui étend la portée du web 2.0 au-delà de la frontière des ordinateurs et des utilisateurs pour lui trouver des domaines d’application dans le monde réel, comprenez par là le terrain.
Web² = Web 2.0 + World
Les explications autour de ce Web² sont résumées dans l’article fondateur suivant : Web Squared: Web 2.0 Five Years On, mais vous pouvez en trouver une lecture plus synthétique ici : The Evolving Web In 2009: Web Squared Emerges To Refine Web 2.0. C’est d’ailleurs de ce dernier article que je tire ce très bon schéma :

Le Web² est donc présenté comme un complément du Web 2.0, une forme de maturation qui va tranquillement nous mener vers la prochaine itération majeure (le fameux Web 3.0 dont les contours sont encore flous). Plusieurs notions fondamentales sont citées dans ce schéma que je vais essayer de vulgariser.
Implied Metadata : des métadonnées générées automatiquement et des systèmes auto-apprenants
Le web est aujourd’hui une véritable mine d’or d’informations. A tel point que le commun du mortel est confronté au problème d’infobésité : une surabondance d’informations qui perturbe la recherche d’informations à valeur ajoutée. Pour nous aider dans cette tâche de traitement de cette masse colossale d’informations, nous avons besoin de métadonnées (des données qui décrivent les données). Prenons l’exemple d’une photo de la Tour Eiffel, n’importe qui saura que cette photo a été prise à Paris, n’importe quel utilisateur humain mais pas les machines ! Pour qu’un service ou un agent intelligent puisse savoir que telle photo représente la Tour Eiffel et qu’elle a été prise à Paris, il faut lui préciser. Oui mais voilà, c’est un travail laborieux. Heureusement sont apparus des appareils photo numériques capables d’associer tout un tas de données aux photos comme par exemple les coordonnées GPS ou le modèle de l’appareil. Ces données ne sont pas directement accessibles à l’utilisateur mais elles sont disponibles pour qui veut bien se donner la peine de les chercher.
Ce type de métadonnées ne représente aux yeux de l’utilisateur que très peu de valeur, sauf si elles sont collectées et exploitées dans un contexte structurant comme par exemple sur FlickR où il est possible de parcourir les photos de la communauté en fonction de l’endroit où elles ont été prises (sur une carte du monde) ou en fonction du type d’appareil photo. Vous obtenez ainsi un très bon outil d’analyse du parc d’appareils photo numériques en circulation sans que les utilisateurs aient eu à saisir ces données, elle sont implicites (d’où la notion d' »implied metadata« ).
Mais cela va plus loin avec les systèmes auto-apprenants qui sont capables de générer des métadonnées à partir de recoupements. Reprenons l’exemple de nos photos numériques : si vous souhaitez les classer en fonction des personnes qui sont prises en photo, il faut toutes les parcourir à la main pour mettre de côté celles qui vous intéressent. Sauf si vous avez recours à un logiciel de reconnaissance faciale qui va faire ce travail à votre place : vous lui donner 2 ou 3 exemples pour qu’il reconnaisse un visage et il vous propose ensuite une liste de suggestions à valider. C’est le principe mis en œuvre par iPhoto 09.

L’article de Tim O’reilly cite l’exemple d’un chauffeur de taxi en Nouvelle-Zelande qui a trouvé un façon très rentable d’exploiter les métadonnées implicites : ce dernier a enregistré pendant 6 semaines un certain nombre de données sur ses courses (nombre de passagers, coordonnées GPS des points de départ et arrivée, conditions climatiques, horaires…), en a fait une compilation puis une analyse afin de déterminer les quartiers le plus rentables en fonction de l’heure de la journée.
Les métadonnées implicites comme facteur de croissance du C.A., une belle promesse, non ? Et il est possible de trouver de nombreux autres domaines d’application grâce aux données potentiellement fournies par des capteurs (votre téléphone ou n’importe quel objet équipé d’une puce RFID ou ZigBee peut faire l’affaire). Il en va de même pour les compteurs intelligents qui vont remonter des données très précieuses sur les habitudes de consommation des foyers (notion de « Smart Electric Grid » possible car chaque appareil émet une signature électrique unique). Ce type d’équipement permet ainsi à votre fournisseur d’énergie de mieux anticiper la consommation (et donc son approvisionnement) ainsi que de vous faire des recommandations pour optimiser votre facture.

Bien évidemment tout ceci est encore en train de se mettre en place mais il semblerait qu’une norme commune soit déjà en train d’émerger : MQTT, un protocole pour standardiser les communications de machine à machine (cf. MQTT Poised For Big Growth – an RSS For Internet of Things?).
L’auteur nous met néanmoins en garde contre l’accumulation de ces données et les problèmes d’exploitation qui peuvent en découler : ce sont des données brutes, elles doivent être traitées et présentées de façon adéquate pour être compréhensibles et représenter une réelle valeur. D’où l’importance de systèmes de visualisation suffisamment souples et intuitifs pour permettre une manipulation aisée. Des services comme Gap Minder nous montrent ainsi la voie : mettre à disposition des données brutes (Ex : Data.gov) et fournir les outils pour les manipuler et en tirer du sens.
Information Shadow : des infos pour chaque objet, personne, lieu…
Autre notion importante, celle d’Information Shadow qui décrit l’ensemble des informations et données associées à un objet, une personne, un lieu, un événement… Ces informations sont disponibles n’importe où (data-on-the-cloud), il suffit juste d’avoir le bon lecteur pour les visualiser. Prenons un exemple que vous connaissez tous : le code barre. En passant un scanner dessus, vous obtenez la désignation, le prix… Même principe pour les mobile tags et autres flashcodes qu’il suffit de prendre en photo avec votre téléphone pour obtenir des infos complémentaires (cinémas les plus proches et horaires pour un film, ressources complémentaires pour un article…). Nous n’en croisons pas beaucoup pour le moment mais attendez-vous à une montée en puissance très rapide grâce notamment à des lecteurs universels comme le BeeTagg Multicode Reader ou à l’impulsion de gros acteurs comme Microsoft avec son Tag.

Autre possibilité et pas des moindres, le recours à des applications de réalité augmentée en situation de mobilité comme celle que propose Layar : en regardant le monde au travers de la caméra de votre téléphone, vous avez accès à une multitude de couches de données supplémentaires qui viennent enrichir la réalité.

Exemple d’application de réalité augmentée avec Layar
Ce ne sont que des exemples et encore une fois les domaines d’application sont nombreux, de même que les supports.
Real-Time Web : informations et interactions sociales en quasi temps réel
Autre phénomène majeur de ces derniers mois, l’avènement du web temps réel avec notamment les outils de microblogging comme Twitter. L’idée derrière cette notion est que les outils mis à la disposition de la foule (accessibles au travers d’un ordinateur ou de terminaux mobiles) permettent l’émergence d’une conscience collective qui réagit en quasi temps réel aux événements extérieurs. Le facteur le plus important dans ce web en temps réel est la remontée d’informations ultra- fraiches directement sur le terrain, comme par exemple lors des dernières manifestations en Iran.

Cela fonctionne aussi bien pour les news que pour les événements (tweets lors de conférences, concerts ou défilé du 14 juillet), pour le marketing (avec des outils de monitoring de la statusphère), pour les interactions sociales avec des solutions de syndication en temps réel comme Echo (cf. Vers des commentaires distribués pour les blogs ?).
Bref, l’échelle de temps est de plus en plus courte et cela s’applique d’autant mieux sur des plateformes sociales à grande échelle. Il y a à ce sujet une théorie très intéressante autour du Synaptic Web (en référence aux synapses qui relient les neurones entre eux) qui décrit les plateformes sociales de type Facebook ou Twitter comme des cerveaux « sociaux » où les membres (les neurones) interagissent en très grand nombre et avec des temps de réaction toujours plus courts (RT, commentaires, notes…). Bref, c’est de l’intelligence collective en quasi temps réel, le tout étant de trouver les bons outils de surveillance / interprétation des ces échanges (pour faire le tri entre bruit et signaux).
Data Ecosystems : des bases de connaissances structurées, ouvertes et universelles
Dernière grosse notion du Web² : les écosystèmes de données qui permettent de relier entre elles des bases de connaissances qui étaient auparavant cloisonnées. Pour comprendre le fonctionnement de ces Data Ecosystems, il me faut d’abord vous expliquer deux notions sous-jacentes : les Linked Data et les Data Sets.
Le terme Linked Data est utilisé pour décrire une méthode de partage et de connexion de données entre elles. Jusqu’à présent, pour relier deux données entre elles il fallait faire un lien depuis une donnée A vers une donnée B avec une URL (ex : Un clic sur ce lien ‘Fred Cavazza‘ mène à mon profil sur LinkedIn). Cette forme de connexion présente de nombreuses contraintes car elle est trop formelle et surtout limitée (un lien ne permet de relier entre elles que 2 données). C’est à la fois très puissant pour les utilisateurs (qui sautent de pages en pages) mais très pauvre pour les machines et agents intelligents (qui doivent parcourir le web dans tous les sens pour lier un grand nombre de données entre elles). L’idée derrière les Linked Data est de proposer un mécanisme plus souple et surtout plus puissant qui repose sur 4 principes :
- Utiliser des URIs et non des URLs (un identifiant unique bien qui autorise de la granularité) ;
- Utiliser des adresses http pour un accès universel (aussi bien pour les utilisateurs que pour les machines) ;
- Structurer les informations sur la ressource à l’aide de métalangage comme RDF ;
- Lier ces informations à d’autres données (via des URIs).
Dans les faits : vous avez un article qui parle de Berlin, vous pouvez soit mettre un lien URL sur le mot Berlin qui pointe vers la page Wikipedia (utile pour les utilisateurs mais par pour les machines car ce sont des informations non-structurées), soit mettre un lien URI qui pointe vers les Linked Data de Berlin (avec des données structurées très utiles pour les machines mais bien trop dures à lire pour les utilisateurs).

Ne vous y trompez pas : les Linked Data ne sont pas l’avenir du web semantique, c’est « simplement » une façon de sémantiser le web. Mais je ne voudrais pas m’enliser dans des explications complexes sur les subtilités entre Linked Data et Semantic Web.
Les Data Sets sont des groupes de données qui sont connectées entre eux (les groupes). Pour faire simple : IMDB est une gigantesque base de données sur l’industrie du cinéma, par contre elle n’est pas nécessairement ouverte à l’extérieure (il faut avoir un compte premium il me semble). Les Data Sets sont des bases de données qui sont liées entre elles grâce aux Linked Data, chaque donnée enrichit les autres et multiplie ainsi la valeur du tout. Fabrice Epelboin donne une très belle métaphore dans son article : « Les données étaient autrefois enfermées, comme des fleurs dans des serres. Ce que l’on propose ici, c’est de les faire pousser en plein air, de façon à ce qu’une multitude d’abeilles non seulement se chargent de la polénisation pour le compte des fleuristes, mais qu’on puisse créer du miel et la profession d’apiculteur ».
Bien évidemment cela représente un chantier titanesque mais les travaux progressent à grand pas, notamment sous l’impulsion de Sir Tim Berners Lee dont vous pouvez voir ici une présentation parlant des Linked Data au TED :
http://video.ted.com/assets/player/swf/EmbedPlayer.swf
L’objectif des Data Ecosystems est donc de créer de gigantesques bases de bases de données, ou plutôt une méta base de données qui les regroupe toutes :

L’idée étant que l’on puisse créer de la valeur en liant des données de différents horizons (médicales, culturelles…). Signalons ainsi des initiatives remarquables comme :
- Le projet Gutenberg, une bibliothèque universelle (sorte de Google Books mais en open source) ;
- dbPedia, une communauté qui se charge de structurer les informations de Wikipedia en données « compatibles » avec Linked Data (regardez donc le cadre à droite de certaines fiches, les infobox, ce sont des données tructurées) ;
- Jamendo, une plateforme musicale entièrement en Creative Commons qui a publié son catalogue sous forme de Data Sets / Linked Data (exploitables avec dbTunes).
Ce ne sont que quelques exemples mais ils témoignent de l’ampleur de la tâche et de l’engagement des membres.
Vous l’aurez donc compris, le web sémantisé n’est pas pour tout de suite mais les différents grands acteurs se mettent en rang pour terminer cette conversion au plus vite. Linked Data et Data Sets ne sont qu’un exemple d’initiatives concourant à la création de Data Ecosystems mais il en existe d’autres comme par exemple le format CommonTag qui vise à standardiser l’utilisation des tags (cf. Common Tag apporte un standard aux métadonnées).
Pourquoi parler du Web Squared ?
Tout simplement parce qu’il est inimaginable de penser évangéliser le marché avec des termes jargonnant comme Information Shadow, Linked Data, Implied Metadata… il faut employer un terme simple qui puisse aider le commun des mortels à comprendre que nous sommes en train de vivre une nouvelle bascule (tout comme cela a été le cas avec le Web 2.0).
Je suis persuadé que nous sommes pratiquement arrivé au bout de ce que le web peut nous offrir en terme de partage de documents / contenus de même que pour les interactions sociales. Il existe encore de nombreux services et domaines d’application à trouver dans ces deux domaines mais nous avons déjà fait le plus gros. Nous sommes déjà en train de vivre la prochaine grosse itération du web : le web en temps réel, la réalité augmentée, les objets communicants, les écosystèmes de données sont des innovations en cours de maturation qui vont complètement bouleverser notre façon de communiquer, consommer, travailler, nous divertir… Bref, un nouveau paradigme des usages du web.
Pour marquer cette itération, nous avons besoin d’éduquer le marché (utilisateurs, annonceurs, opérateurs, pouvoirs publics…) et pour cela il faut pouvoir capitaliser sur un terme simple : le Web² (Web Squared).
Et maintenant ?
Maintenant tout reste à faire ! Ou plus précisément le travail d’évangélisation ne fait que commencer. Je vous engage ainsi à vous familiariser avec ces différentes notions et de prendre le temps d’en tester les applications pour bien appréhender la (r)évolution qui approche.